

- 应用技术领域
- 大容量连续语音识别
大容量连续语音识别 (LVCSR)
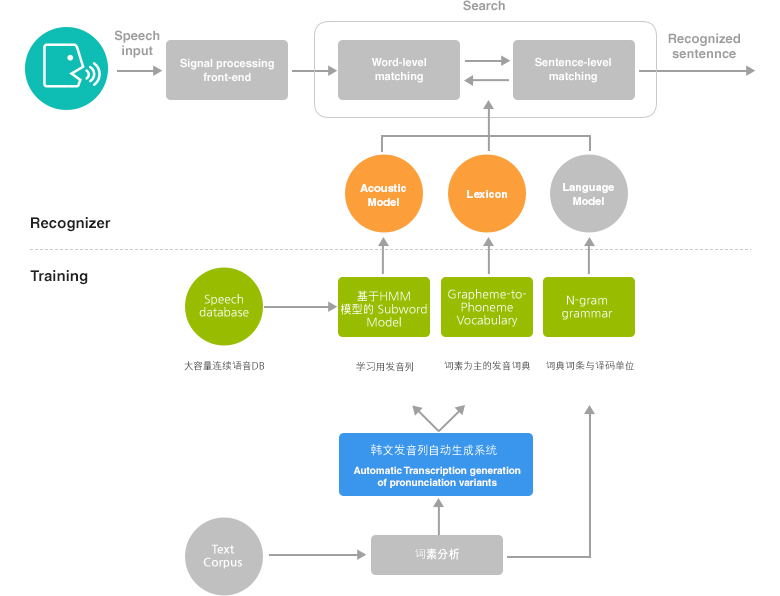
本技术通过音频和语言模式识别话者语音,由20万单词规模组成的大容量连续语音识别系统。 采用Server-Client形态分散语音识别系统,由信号处理与提取特征的前处理部和音响模块、发音词典、以及使用语言模块的导航模块与后处理模块组成。
核心算法
针对反映音韵变化的音响模块和词素分析发音列生成规则算法,词典大小,未登录口令(Out-of-Vocabulary)等因素,将使用最佳语言处理单位的语言模块变化为语音测试的技术。
- 前处理部分
- 去除杂音、提升音质
- 提取语音区间信息
- 提取语音特征参数
- 音响模块
- 根据随时间变化的语音信号特征建模
- 使用HMM, NN模型等
- 发音词典
- 自动生成韩文单词发音列
- 支持多重发音列
- 语言模块
- 针对单词间语法,聚焦识别候补的加权值,让语法无误的文章获得更高分数
- 参考FSN、n-gram等被识别对象词汇的数量和识别速度以及识别性能,选择语言模块
- 基于WFST(Weighted Finite-State Transducer)的Decoder
- 高速/高效内存管理
- Smart convergence/ 开发基于汽车环境特殊口语体n-gram的LM(Language model)
- 后续处理
- 处理识别结果,提升识别性能或者识别结果可信度的计算模块
技术服务
应用领域
- CONTACT US
- COMPANY
- TECHNOLOGY
- APPLICATION
- SUPPORT&PR
Copyright⒞2014 POWERVOICE. All Right Reserved.